A minimal, educational implementation of Flash Attention v2 in CUDA. This project demonstrates the core concepts of Flash Attention with a focus on code clarity and understanding.
mini-flash-attention v0.1 is a simplified version that omits some advanced features like causal masking and variable-length sequences. If you are not familiar with Flash Attention, start with this version to grasp the fundamentals.
Flash Attention is a fast and memory-efficient attention algorithm that makes training large models more practical. This is a simplified version that keeps the core ideas while being easier to understand and modify.
Key features:
- Flash Attention v2 algorithm with tiling
- CUDA Tensor Cores for matrix operations
- FP16 and BF16 support
- Variable-length sequences (continuous batching)
- Causal masking
- Flash decoding
Requirements:
- CUDA 11.8+ (tested on CUDA 12.8)
- Python 3.8+
- PyTorch 2.0+
- NVIDIA Ampere GPU or newer (SM 80+)
Build:
git clone https://github.com/w4096/mini-flash-attention.git
cd mini-flash-attention
git submodule update --init --recursive
python setup.py build
export PYTHONPATH=$(pwd)/build/lib.linux-x86_64-cpython-312 # adjust for your Python versionimport torch
from mini_flash_attention import flash_attn_func
# Standard batched attention
q = torch.randn(2, 1024, 8, 128, device='cuda', dtype=torch.float16)
k = torch.randn(2, 1024, 8, 128, device='cuda', dtype=torch.float16)
v = torch.randn(2, 1024, 8, 128, device='cuda', dtype=torch.float16)
output = flash_attn_func(q, k, v, causal=True)For continuous batching (variable-length sequences):
from mini_flash_attention import flash_attn_varlen_func
# Different sequence lengths in one batch
seqlens = [128, 256, 512]
total = sum(seqlens)
q = torch.randn(total, 8, 64, device='cuda', dtype=torch.float16)
k = torch.randn(total, 8, 64, device='cuda', dtype=torch.float16)
v = torch.randn(total, 8, 64, device='cuda', dtype=torch.float16)
cu_seqlens = torch.tensor([0] + seqlens, dtype=torch.int32, device='cuda').cumsum(0)
output = flash_attn_varlen_func(q, k, v, cu_seqlens, cu_seqlens, max(seqlens), max(seqlens))Benchmarked on a NVIDIA RTX 5070 (sm_120) with CUDA 12.8 using the scripts in benchmark. Results can vary across hardware and software.
Prefill (head_dim=128, batch_size=48, num_heads=24):
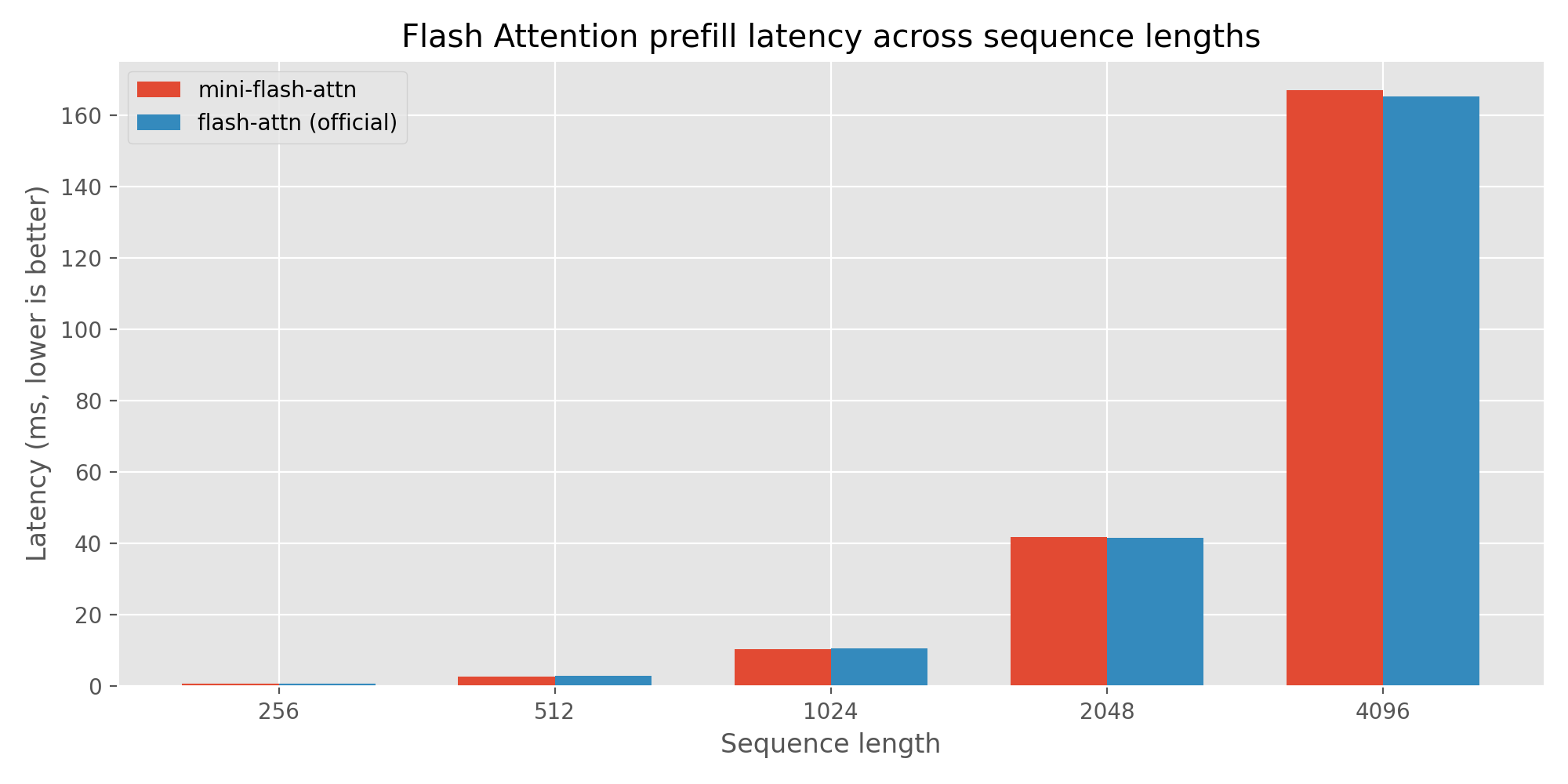
| Sequence Length | Mini Flash Attention | Official Flash Attention | Speedup |
|---|---|---|---|
| 256 | 0.665 ms | 0.779 ms | 1.173x |
| 512 | 2.659 ms | 2.872 ms | 1.080x |
| 1024 | 10.515 ms | 10.746 ms | 1.022x |
| 2048 | 41.818 ms | 41.696 ms | 0.997x |
| 4096 | 167.180 ms | 165.385 ms | 0.989x |
Decoding (head_dim=128, batch_size=24, seqlen_q=1, num_heads=24):
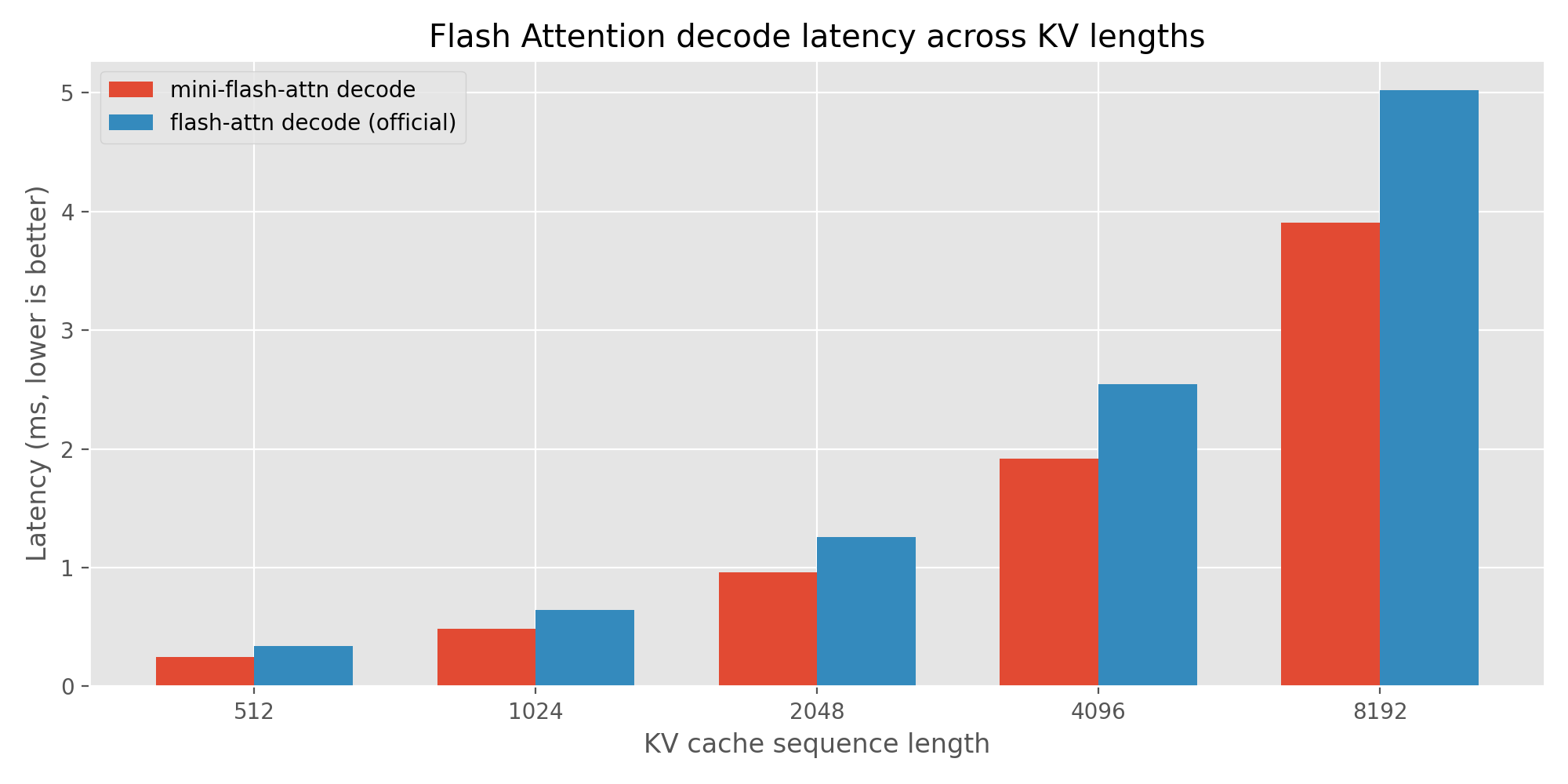
| KV Length | Mini Flash Attention | Official Flash Attention | Speedup |
|---|---|---|---|
| 512 | 0.246 ms | 0.340 ms | 1.383x |
| 1024 | 0.484 ms | 0.645 ms | 1.334x |
| 2048 | 0.963 ms | 1.259 ms | 1.307x |
| 4096 | 1.915 ms | 2.547 ms | 1.330x |
| 8192 | 3.907 ms | 5.023 ms | 1.285x |
Why is mini flash attention faster on decoding?
The mini flash attention only supports the query length of 1 in decoding, In the implementation, we can use vector-matrix multiplication instead of matrix-matrix multiplication. The official implementation supports arbitrary query lengths, if the query length is 1, it will still use matrix-matrix multiplication, which may introduce some overhead.
The API is same as the official Flash Attention implementation, with two three functions:
- Standard batched attention. Supports optional causal masking.
def flash_attn_func(
q: torch.Tensor,
k: torch.Tensor,
v: torch.Tensor,
causal: bool = False,
) -> torch.Tensor:- Variable-length sequences (continuous batching). Supports optional causal masking and block table.
def flash_attn_varlen_func(
q: torch.Tensor,
k: torch.Tensor,
v: torch.Tensor,
cu_seqlens_q: torch.Tensor,
cu_seqlens_k: torch.Tensor,
max_seqlen_q: int,
max_seqlen_k: int,
causal: bool = False,
block_table=None,
) -> torch.Tensor:- Flash decoding with KV cache.
def flash_attn_with_kvcache(
q,
k_cache,
v_cache,
cache_seqlens: Optional[Union[int, torch.Tensor]] = None,
block_table: Optional[torch.Tensor] = None,
num_splits=0,
) -> torch.Tensor:- Implement causal masking
- Support variable sequence lengths
- Support KV cache
- sliding window attention
Based on the Flash Attention v2 paper by Tri Dao (2023). Uses NVIDIA Cutlass/CuTe libraries.