Multi-agent swarms you can actually see, debug, and improve.
![]()
Sequential or parallel multi-agent orchestration on top of LangGraph + the OpenAI API, with three capabilities that most multi-agent frameworks don't bundle together:
What this is not: not a single-agent memory plugin, not a production observability platform (see Langfuse), not a model router (see LiteLLM). swarmweave is a focused scaffold for building multi-agent pipelines where workers need to see each other's work — and you need to see what's happening.
- Live terminal dashboard —
swarmweave watch your_swarm.pyopens a split-screen Rich TUI that streams worker status, tool calls, shared-context flow, and accumulating token cost in real time. No moreprint-statement debugging. - Self-improving via lessons — every successful run can distill 1-5 transferable lessons. The next similar run pre-loads them into shared context. Plain JSONL under
~/.swarmweave/lessons/, fully editable, no telemetry. - Shared-context substrate — workers in sequential pipelines read each other's findings via embedding-based retrieval (default
text-embedding-3-small, automatic Jaccard fallback offline).
git clone https://github.com/manav8498/swarmweave
cd swarmweave
./init.sh
source .venv/bin/activate
export OPENAI_API_KEY=sk-...
swarmweave watch examples/03_support_triage_swarm/main.pyfrom swarmweave import Supervisor, Worker, SharedContext
from swarmweave.backends import LocalBackend
ctx = SharedContext(backend=LocalBackend())
supervisor = Supervisor(
shared_context=ctx,
model="gpt-4o-mini",
mode="sequential", # or "parallel"
workers=[
Worker(name="classifier", role="Categorize the ticket"),
Worker(name="resolver", role="Draft a reply using the category"),
Worker(name="verifier", role="Check the draft against policy"),
],
)
result = supervisor.run("Handle this support ticket: ...")
print(result.final_output)The whole public API is three primitives — SharedContext, Supervisor, Worker. Optional Mentor for cross-run learning, EventBus for custom observability.
Use swarmweave if you're building:
- Sequential pipelines like classify → draft → verify, where later workers genuinely need earlier work
- Multi-specialist reviewers (security / perf / style / coverage) that produce one prioritized output
- Research-style fan-out with shared synthesis
- Anything where you've been fighting LangGraph's state graph to express "worker B reads what worker A wrote"
Don't use it if:
- Your task is a single LLM call — use the OpenAI SDK directly
- You need production observability (traces, eval datasets, dashboards) — use Langfuse or LangSmith
- You need cost/rate guardrails at the proxy level — use LiteLLM
- You need Anthropic/Claude support today — v0.1 is OpenAI API only; Anthropic adapter is planned for v0.2
- Your existing setup works and you're not feeling pain around worker coordination or debugging — switching cost isn't worth it
This library is a focused scaffold, not a replacement for the broader ecosystem.
Most multi-agent systems coordinate through the supervisor. Workers run in private context windows; everything they know about each other has to fit in whatever the supervisor relays at handoff. Re-summarization is lossy, workers redo each other's work, and every additional worker makes the coordination problem worse.
swarmweave replaces that with a thin shared-context layer. In sequential mode, each worker's SharedContext.aread() returns every prior worker's findings — so verifier reads resolver's draft, fixer reads investigator's analysis, etc. In parallel mode, workers fan out simultaneously and the supervisor synthesizes from their collective trace.
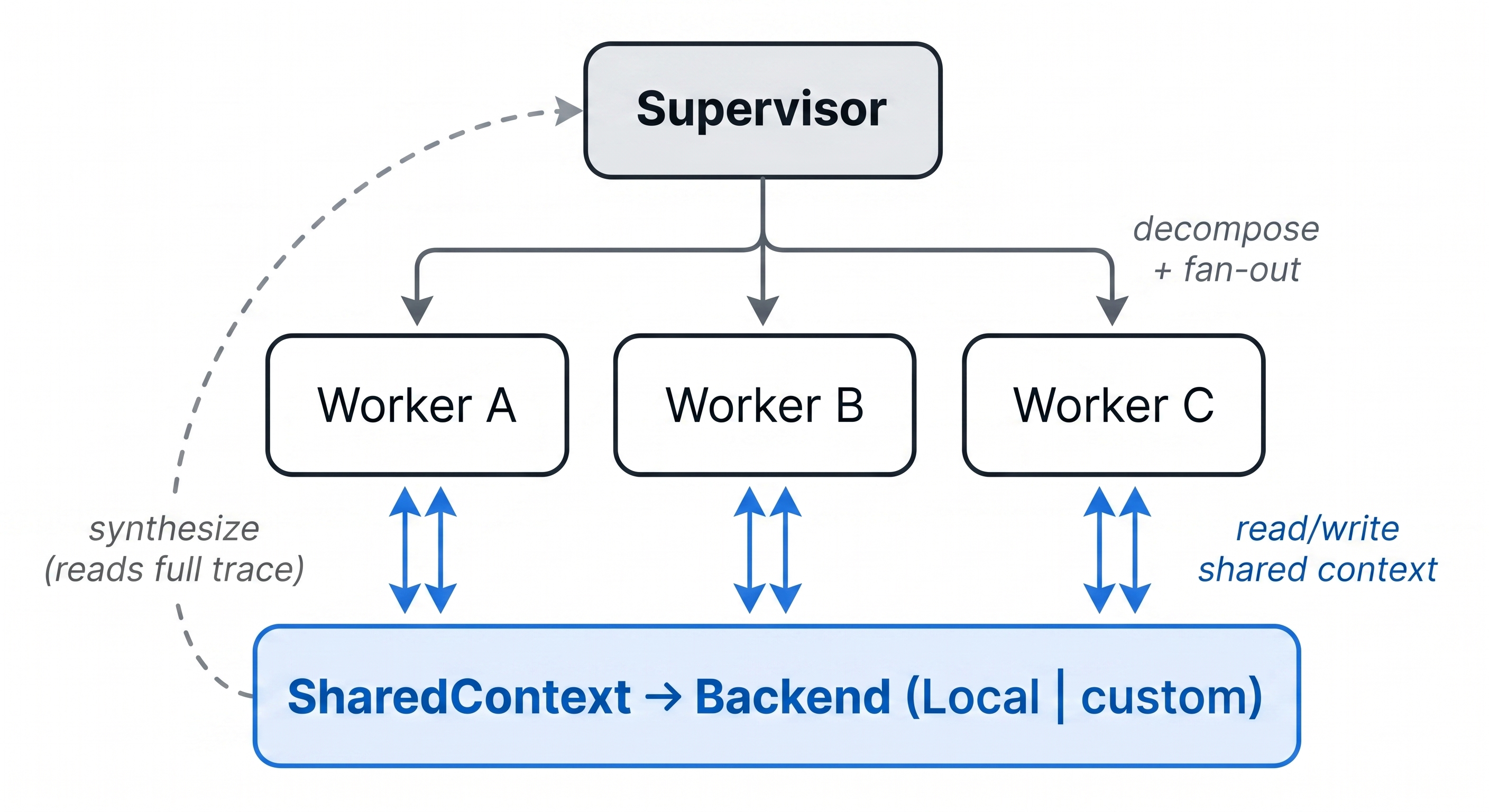
| Class | Role |
|---|---|
SharedContext |
The substrate. aread() returns the slice of past observations most relevant to a task; awrite() appends a new one. Backed by a swappable Backend. |
Supervisor |
Decomposes the task, runs workers (parallel or sequential), synthesizes the final answer, finalizes the outcome. |
Worker |
One specialist. Reads context, autonomously calls tools, writes a finding. Has a forced wrap-up call so reasoning models actually commit to an answer when their tool budget runs out. |
EventBus |
Optional. Streams every event for live observability or custom dashboards. |
Mentor / LessonBook |
Optional. Persistent cross-run memory that makes the swarm self-improving. |
┌────── workers ──────┐ ┌────────── shared-context flow ──────────┐
│ classifier ✓ done │ │ 14:22:01 [supervisor] decompose_done │
│ resolver ⠋ tool │ │ 14:22:14 [classifier] WRITE → billing │
│ verifier · idle │ │ 14:22:30 [resolver] READ ← 1 prior │
└─────────────────────┘ │ 14:23:11 [resolver] tool_call: lookup │
└─────────────────────────────────────────┘
┌─ metrics ───────────────────────────────────────────────────────┐
│ elapsed 02:14 │ calls 12 │ in 8,420 │ out 23,991 │ ~$0.0040 │
└──────────────────────────────────────────────────────────────────┘
Built on Rich. 8 fps refresh. Opt-in via EventBus — zero overhead when unused.
from swarmweave import Mentor
mentor = Mentor(book="customer_support")
await mentor.before_run(supervisor, user_task) # preloads relevant past lessons
result = await supervisor.arun(user_task)
await mentor.after_run(supervisor, user_task, result) # extracts new lessonsLessons live as plain JSONL under ~/.swarmweave/lessons/<book>.jsonl. Fully readable, editable, deletable. No telemetry leaves your machine.
Run examples/04_self_improving_swarm/main.py twice — round 2 reads lessons from round 1. The improvement is demonstrable, not theoretical.
Four runnable examples under examples/. Each is ~80 lines.
| Example | Pattern | What it shows |
|---|---|---|
01_research_swarm |
parallel fan-out | Three researchers + supervisor synthesis |
02_code_review_swarm |
parallel specialists | security / perf / style / coverage → prioritized review |
03_support_triage_swarm |
sequential pipeline | classify → resolve → verify with policy check |
04_self_improving_swarm |
sequential + Mentor | Same task run twice, second round reads first round's lessons |
Watch any of them live in the TUI:
swarmweave watch examples/03_support_triage_swarm/main.pyA 20-task multi-hop benchmark comparing isolated-context (each worker has private memory) against shared-context (workers read each other's findings), sequential mode, same workers, same model, same tools — only the backend differs.
What shared context demonstrably changes in each run:
- Worker B reads Worker A's reasoning, not just the original task — a resolver building on a classifier's output uses the actual classification rationale, not a re-statement of the user's query.
- Verifiers correct based on actual prior work — a policy-check step reads what the resolver drafted and cites specific lines, instead of checking a hypothetical.
- Lessons accumulate across runs — the second run of the same task pre-loads distilled findings from the first, compressing warm-up time.
On raw accuracy: across runs on this 20-task benchmark at gpt-4o-mini, both modes landed in the 85–100% range — essentially tied within model variance. Simple multi-hop factual accuracy is not where the coordination wins show up. The wins are in reasoning chain quality, less duplicated work between workers, and verifier precision — qualitative differences the TUI makes visible and the accuracy rubric only partially captures.
To see the difference concretely, run examples/03_support_triage_swarm/main.py and watch the shared-context flow panel. Or use scripts/real_world_review.py to A/B test both modes against your own codebase.
Reproduce with:
python benchmarks/run_benchmark.pyFull methodology, rubric, and per-task results are in benchmarks/README.md.
pip install swarmweaveOr from source:
git clone https://github.com/manav8498/swarmweave
cd swarmweave
# macOS / Linux
./init.sh && source .venv/bin/activate
# Windows (PowerShell)
./init.ps1
# Cross-platform alternative (works anywhere Python is)
python -m venv .venv && source .venv/bin/activate # or .venv\Scripts\Activate.ps1 on Windows
pip install -e ".[dev]"
export OPENAI_API_KEY=sk-...Requirements: Python 3.11+, an OpenAI API key. Default model is gpt-4o-mini — cheap, fast, available to every account.
Cost note: The examples under
examples/and the benchmark underbenchmarks/call the real OpenAI API. Withgpt-4o-minidefaults, a full example run costs roughly $0.001–$0.01; the full 20-task benchmark costs roughly $0.05–$0.20. No telemetry is sent anywhere else.
| LangGraph | CrewAI | AutoGen | swarmweave | |
|---|---|---|---|---|
| Graph orchestration | ✅ | partial | partial | ✅ (built on LangGraph) |
| Sequential workers see each other's findings | manual | partial | manual | ✅ via SharedContext |
| Live terminal UI | — | — | — | ✅ swarmweave watch |
| Cross-run learning | — | partial | — | ✅ Mentor + LessonBook |
| Embedding retrieval as default | — | configurable | — | ✅ text-embedding-3-small |
| Forced wrap-up when reasoning models loop | — | — | — | ✅ |
| Apache-2.0, no telemetry | ✅ | ✅ | ✅ | ✅ |
We sit on top of LangGraph, not against it. Bring an existing LangGraph app and compose build_swarm_graph(supervisor) as a sub-graph.
For persistent memory of a single agent's session, see also claude-mem. For cross-run learning in a different orchestration style, see agent-swarm. swarmweave differs in the retrieval model (embedding + recency vs. flat append) and the shared-context layer that connects workers within a run, not just across runs.
docs/architecture.md— the thesis, why shared context mattersdocs/api_reference.md— every public class and methoddocs/custom_backends.md— bring your own retrieval backend in ~80 linesCHANGELOG.md— release history
- v0.1 (this release) —
LocalBackendwith embeddings + Jaccard fallback, LangGraph adapter, sequential/parallel modes, live TUI,Mentor/LessonBook,EventBus, four example swarms, reproducible benchmark. - v0.2 — OpenAI Agents SDK adapter and
swarmweave replay <session>for post-run inspection. - v0.3 — Anthropic Agent SDK adapter, MCP-tool support in
Worker, durable cross-process sessions, production-grade cost guardrails.
PRs welcome. See CONTRIBUTING.md for dev setup and the lint/type/test gates, and CODE_OF_CONDUCT.md.
Please report vulnerabilities per SECURITY.md. Do not open public issues for suspected security bugs.
Apache-2.0. See LICENSE.
swarmweave is an independent open-source project by @manav8498. Issues and PRs welcome.