Checks
Environment Details
runpod/pytorch:2.4.0-py3.11-cuda12.4.1-devel-ubuntu22.04
Steps to Reproduce
This is the training config that I use with my dataset of 130 hours of clean Serbian speech:
exp_name: F5TTS_v1_Base
tokenizer: char
mixed_precision: bf16
learning_rate: 7.5e-05
batch_size_per_gpu: 20189
batch_size_type: frame
max_samples: 64
grad_accumulation_steps: 1
max_grad_norm: 1
epochs: 434
num_warmup_updates: 3779
save_per_updates: 5000
keep_last_n_checkpoints: 1
last_per_updates: 10000
logger: tensorboard
dataset: serbian
finetune: false (training from scratch)
dataset_size: 60,948 samples / 132.05 hours
gpu: NVIDIA A40 (46GB)
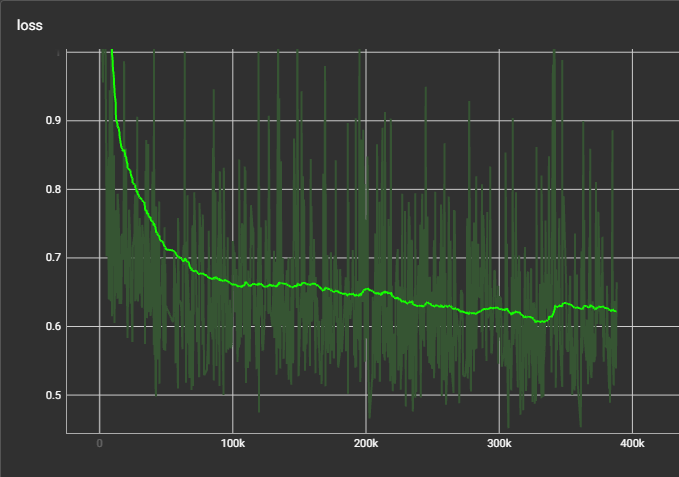
after 3 days of training and ~400k steps, inferenced audio is still halucinating and repeating some parts of the word or the whole words, sometimes also unintelligible.
Loss curve
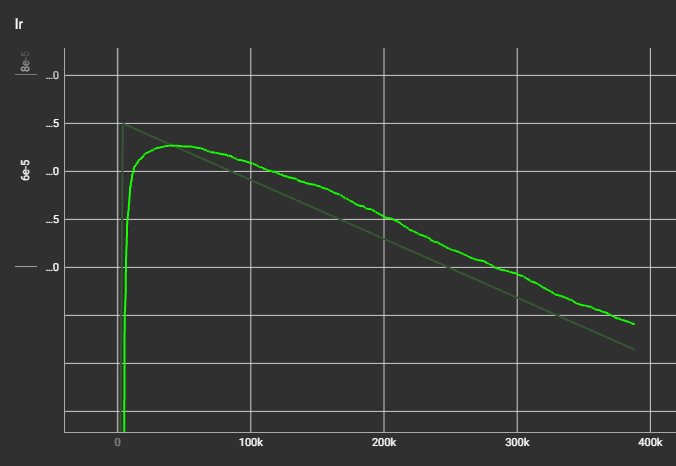
Learninig rate
✔️ Expected Behavior
referenced audio: https://voca.ro/1iSJaiUm5CHz
referenced text: u tom komitetu dobijamo vrlo vrlo opširne biografije kandidata, sa kojima vodimo razgovor i biramo ih, čak i ispitujemo.
❌ Actual Behavior
inferenced text: (same as referenced text)
inferenced audio: https://voca.ro/1mT0JkcugloJ
(this is with EMA enabled, without EMA is much worse)
Checks
Environment Details
runpod/pytorch:2.4.0-py3.11-cuda12.4.1-devel-ubuntu22.04
Steps to Reproduce
This is the training config that I use with my dataset of 130 hours of clean Serbian speech:
after 3 days of training and ~400k steps, inferenced audio is still halucinating and repeating some parts of the word or the whole words, sometimes also unintelligible.
Loss curve

Learninig rate

✔️ Expected Behavior
referenced audio: https://voca.ro/1iSJaiUm5CHz
referenced text: u tom komitetu dobijamo vrlo vrlo opširne biografije kandidata, sa kojima vodimo razgovor i biramo ih, čak i ispitujemo.
❌ Actual Behavior
inferenced text: (same as referenced text)
inferenced audio: https://voca.ro/1mT0JkcugloJ
(this is with EMA enabled, without EMA is much worse)